
La AudiologIA (I): Procesado de señal
Estamos en un momento interesante, la tecnología está avanzando rápido y permitiéndo que se puedan hacer cosas que nunca antes se pudieron. Hay mucho "Hype" muchos IA-optimistas y muchos IA persimistas. La verdad es que estamos a las puertas de una transformación que redefinirá la audiología tal como la conocemos: la irrupción de la Inteligencia Artificial (IA) en sus varias formas. Para la presentación que hice en el II Simposio de Phonak llamé a esto la AudiologIA (ya lo sé, suena tonto, pero no me juzguen por mi humor) . Las oportunidades para la tecnología y los servicios auditivos son inmensas, prometiendo un futuro de intervenciones más precisas, personalizadas y eficientes.
La Inteligencia Artificial, en su esencia, es un conjunto de herramientas y algoritmos que permiten a las máquinas aprender de los datos, reconocer patrones y tomar decisiones. El impacto de esta tecnología ya se siente en tres pilares fundamentales de la audiología: el procesamiento de señal de audio, el análisis de datos y fenotipado profundo, y la colaboración con agentes IA en la prestación de servicios
El Procesamiento de Señal Impulsado por la IA
Durante años, la comunidad audiológica ha sostenido una premisa:
“La reducción de ruido en el audífono ha llegado al máximo”.
Hoy, con los siguientes 5 argumentos, te explico por qué (una pista: "EN" el audifono).
1. Reducción de Ruido con Inteligencia Artificial
Para reducir el ruido de manera eficiente, un audífono debe distinguir con precisión entre lo que es ruido y lo que es palabra. Las redes neuronales profundas (Deep Neural Networks o DNNs) han revolucionado esto, permitiendo entrenar algoritmos para detectar y estimar el ruido con una fidelidad sin precedentes (Andersen, A. H. et al., 2021). La combinación de esta reducción de ruido efectiva con la tecnología direccional clásica permite alcanzar reducciones en la relación señal/ruido (SNR) de hasta unos 10 dB en ambientes sonoros complejos, un nivel nunca antes visto.

2. Reconocimiento de Escenas Sonoras Avanzado
Desde mediados de los 2000, los audífonos han contado con clasificadores de escenas sonoras para ajustar sus parámetros automáticamente. Sin embargo, el enfoque "determinístico" no es eficiente. El aprendizaje automático (Machine Learning) se presenta como la opción óptima para la clasificación. La precisión en la identificación de ambientes depende críticamente de la calidad de los datos de entrenamiento y los algoritmos utilizados (Hayes, D., 2021).
3. Modelado Fiel del Sistema Auditivo
Los modelos auditivos, como la fórmula NAL-NL, han sido fundamentales para compensar la pérdida auditiva, combinando modelos de inteligibilidad y sonoridad. Ahora, el aprendizaje automático permite implementar modelos más complejos y fieles a la fisiología de la audición normal y patológica. El objetivo es normalizar la audición, trascendiendo la mera audibilidad o sonoridad. Ver Wen, Torfs and Verhulst (2025) para más información.
4. Reducción de Ruido Audiovisual
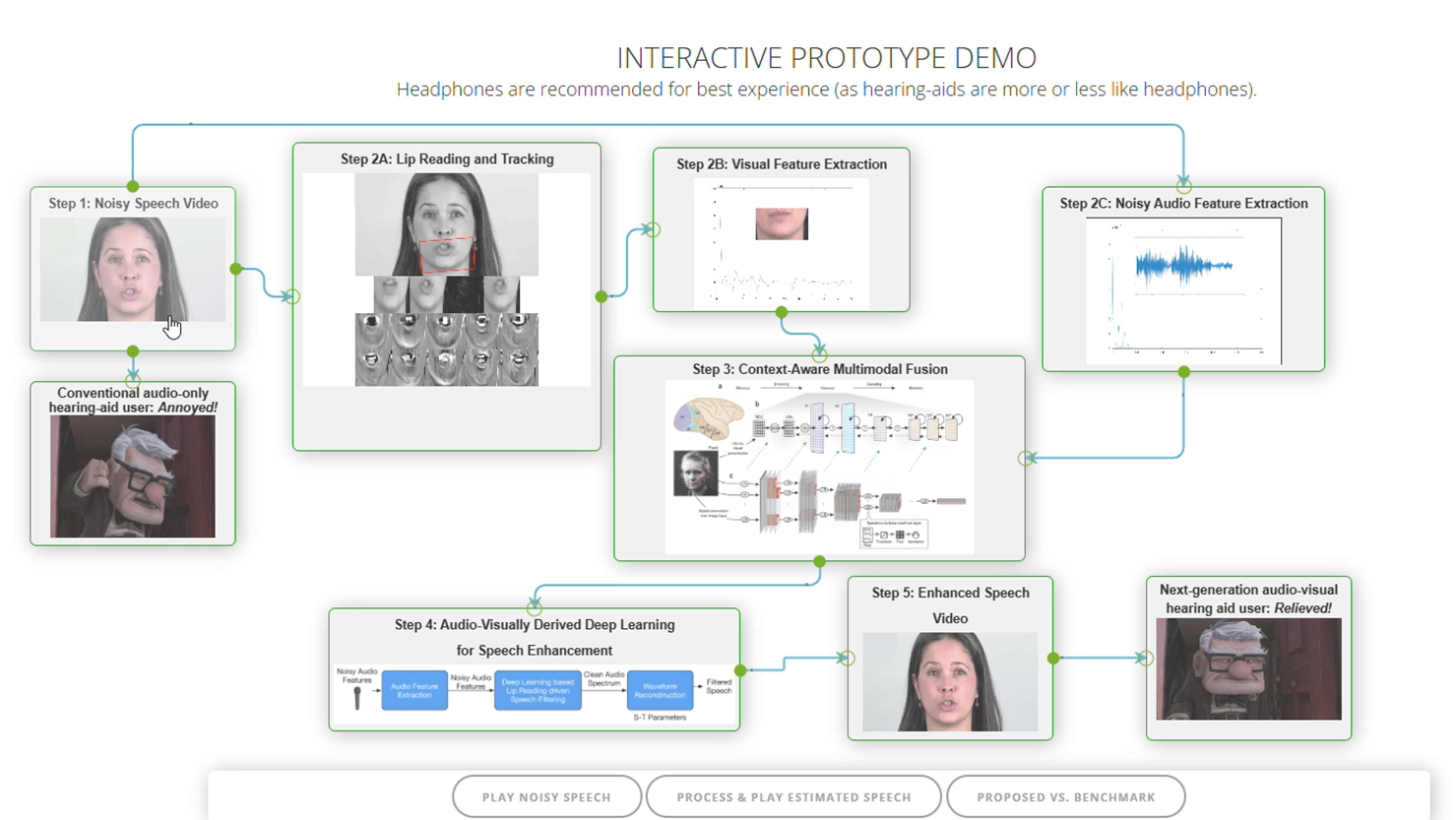
Los algoritmos son ahora capaces de decodificar los movimientos faciales y de la boca para estimar el discurso. Esta tecnología, utilizada en la generación de subtítulos, se aplica a la reducción de ruido. La integración de dispositivos visuales con cámara (como las gafas Rayban Meta) con los audífonos promete resultados impresionantes al combinar la información auditiva y visual para aislar la señal de interés.
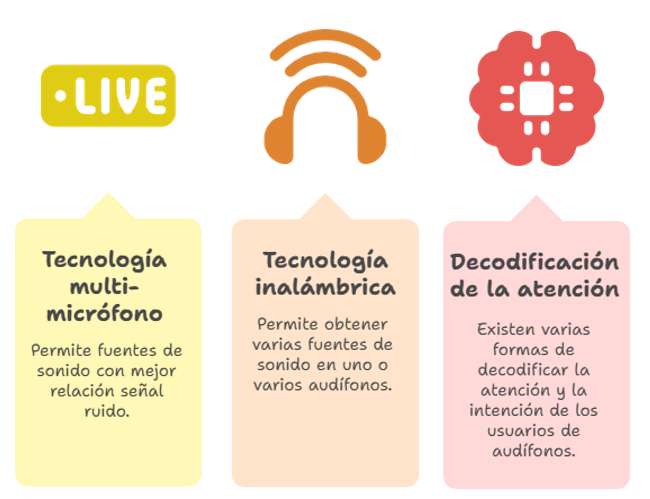
5. Tecnología Multi-Micrófono y Decodificación de la Atención
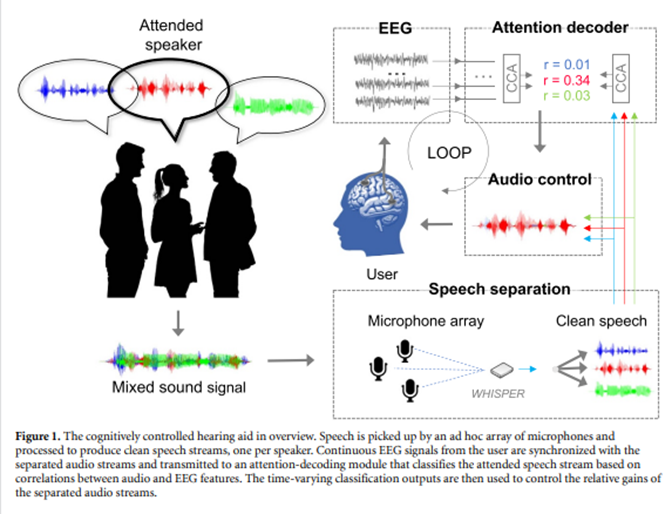
La tecnología multi-micrófono y la conectividad inalámbrica permiten capturar múltiples fuentes de sonido. Aún más importante, existen diversas formas de decodificar la atención y la intención del usuario en tiempo real: mediante eye-tracking (seguimiento ocular), sensores de movimiento, o el Ear-EEG (registro de la señal neural desde el oído). Ver Hjortkjær, J. et al. (2025) para más información. Esto permite un control en "tiempo real" (bueno, casi) del audífono basado en la atención del usuario.
Tres Predicciones Clave para el Futuro (I)
Predicción #1: Énfasis en la Calidad de la Señal (Cuándo, a Quién y Cómo) La tecnología auditiva dejará de centrarse en la cantidad de mejora de señal/ruido y se enfocará en el cuándo, el a quién y el cómo proporcionar esa mejora, gracias a la decodificación de la intención y la atención del usuario entre otras cosas.
Referencias
- Andersen, A. H. et al (2021). Creating Clarity in Noisy Environments by Using Deep Learning in Hearing Aids. Seminars in Hearing, 42(03), 260-281.https://doi.org/10.1055/s-0041-1735134.
- Hayes, D. (2021). Environmental Classification in Hearing Aids. Seminars in Hearing, 42(03), 186-205.https://doi.org/10.1055/s-0041-1735175.
- Hjortkjær, J., Wong, D. D. E., Catania, A., Märcher-Rørsted, J., Ceolini, E., Fuglsang, S. A., Kiselev, I., Di Liberto, G., Liu, S.-C., Dau, T., Slaney, M., & de Cheveigné, A. (2025). Real-time control of a hearing instrument with EEG-based attention decoding. Journal of Neural Engineering, 22(1), 016027.https://doi.org/10.1088/1741-2552/ad867c.
- Wen, Torfs and Verhulst (2025). arXivUS12212929B2.



Member discussion